コンピュータにとって全てのデータは「0」と「1」の組み合わせにすぎません。文字データも例外ではありません。
コンピュータ内部では「0」と「1」の組み合わせである文字データを、ディスプレイに文字として表示するには文字のイメージが必要になります。
ひとつひとつの文字のイメージのことをグリフといい、グリフの集合をフォントといいます。
話を簡単にするために、たとえ話をしましょう。
ある国で使われている文字は「甲」、「乙」、「丙」、「丁」のたった4種類だとします。
この国のコンピュータでは、この4種類の文字さえ扱えればいいとします。
この4個の文字からなる文字集合を符号化(エンコード)してみましょう。
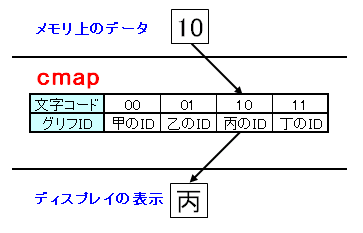
メモリ上やハードディスク内など、コンピュータ内部では文字データは必ず「00」、「01」、「10」、「11」のいずれかです。
これを人間がわかるようにディスプレイに表示するためにはどうしたらよいでしょうか?
今回の例では、「甲」、「乙」、「丙」、「丁」という4つの字形データ(グリフ)を持ったフォントファイルが必要になります。
フォントファイルの中では、それぞれのグリフはグリフIDという番号で識別されます。
フォントファイルには、字形データ以外にも、cmapと呼ばれる文字コードとグリフIDの対応テーブルを持っていて、これにより、文字コードがグリフIDに変換され、グリフIDを元に字形データが読み込まれ、画面に該当する文字が描画されるのです。
上記の例では、エンコーディングが一つでしたが、現実の世界では同じ文字に対して異なるエンコーディングが存在します。
例えば、Windows-31Jで「あ」を表すビット列(「0」と「1」の並び)と、UTF-8で「あ」を表すビット列は異なります。
もし同じcmapを使用するなら、それらは異なるグリフIDに紐付けられ、結果として画面に描画される文字が違ってしまいます。
そのため、cmapでは、さまざまなエンコーディング向けに複数のサブテーブルを持っていて、エンコーディングに応じて使い分けられるようになっています。
|






|