Unicode 〜UTF-8、UTF-16との違い〜
トップ
>
読み物
> (文字コード関連)Unicode 〜UTF-8、UTF-16との違い〜
UnicodeとUTF-8、UTF-16との違いもこれでスッキリ!!
UnicodeとUTF-8、UTF-16との違いはなんでしょうか?
ここでは、あまり詳細にはこだわらず、これらの概念を整理してみたいと思います。
まず
Unicode
。
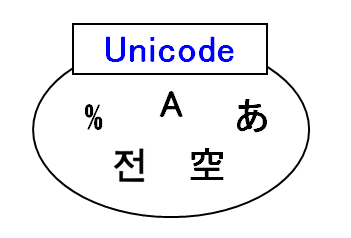
これは
文字集合
です。アルファベットや記号はもちろん、漢字やひらがな、ハングルやヘブライ文字など、世界中で使われている文字を集めたものです。
次に
UTF-8
と
UTF-16
。
これらはUnicodeで定義されている一つ一つの文字を、どのように符号化するかという
文字符号化方式
(
エンコーディング
)です。
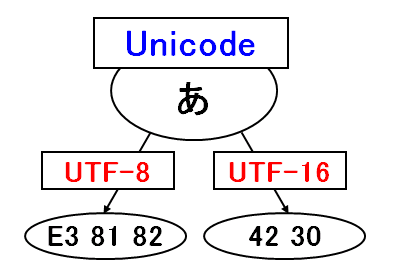
たとえば、Unicodeで定義されている「あ」という文字を、UTF-8とUTF-16で符号化すると下記のようになります(16進数表記)。
Unicodeという一つの文字集合に対して、異なる文字符号化方式UTF-8、UTF-16が存在し、符号化した結果も異なります。
どうしてUnicodeという一つの文字集合に対して、異なる文字符号化方式が存在するのかといえば、そこには歴史的な経緯があり、それぞれの文字符号化方式に長所・短所があるので、目的に応じて使い分けられています。
UTF-8とUTF-16それぞれの特徴を下表にまとめます。
UTF-8
UTF-16
・ASCIIに対して上位互換となっている。
・ASCII互換部分は1バイトである反面、漢字や仮名などの表現に3バイトを要する。
・バイト単位の入出力を行うため、バイト順の影響がない。
・BMP(
※
)内の文字は2バイト、BMP以外の文字は4バイトで表す。
・バイト単位の入出力でバイト順を識別するためのBOM(
※
)が必要。
・WindowsXPなどの内部コード
繰り返しになりますが、Unicodeというのはあくまで文字集合であって、実際に文字をデータとしてファイル等に保存する場合にはUTF-8やUTF-16といった文字符号化方式を使います。
ところが!!
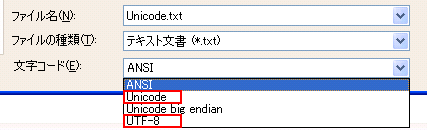
Windowsメモ帳の保存ダイアログの「文字コード」セレクトボックスでは、「UTF-8」の他に「Unicode」が選択できるようになっています。
なぜ、保存(エンコーディング)するのに文字集合である「Unicode」が選択できるのでしょうか?
実は、ここでいう「Unicode」とは「
UTF-16
」を指しています。
文字コード「Unicode」を選んで保存すると、実際には「UTF-16」でエンコードされて保存されます。
まぎらわしいので、「UTF-16」と表示してほしいですね。
sakuraエディタなどでも同様に保存ダイアログで「Unicode」を「UTF-16」と同じ意味で使っています。
ちなみに上図の文字コードの選択肢「ANSI」という表示もおかしくて、正しくは「
CP932
」です(CP932については
Shift_JIS、CP932、MS932、Windows-31J
をご覧ください)。
※
上記の説明では簡便にするため、
エンディアン
や
BOM
、また
BMP
については触れていません。
エンディアンやBOMについては、
Unicode 〜エンディアンとBOM〜
を、BMPについては
Unicode 〜UCS-4とUCS-2〜
をご覧ください。
トップ
>
読み物
> (文字コード関連)Unicode 〜UTF-8、UTF-16との違い〜
トップ
|
このサイトについて
|
管理者へメール
|
サイトマップ
www
una.soragoto.net
Copyright(c) 2009 - 2012 una All Rights Reserved.