Unicode 〜UTF-8、UTF-16との違い〜では、Windowsメモ帳の保存ダイアログの「文字コード」セレクトボックスにおける選択肢「Unicode」が、実際には「UTF-16」を意味しているというお話をしました。
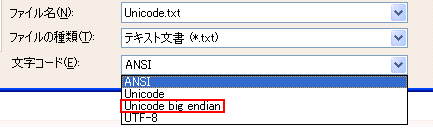
では、選択肢「Unicode」の下にある「Unicode big endian」というのは何なのでしょう?
実はUTF-16には、エンディアンというものの違いにより2種類あり、上のセレクトボックスの選択肢「Unicode」は「UTF-16 リトルエンディアン」を、「Unicode big endian」は「UTF-16 ビッグエンディアン」を意味しています。
では、エンディアンとは一体何なのでしょう?
エンディアンとは、多バイトのデータをメモリ上に配置する方式のことです。
上位バイトから順番にメモリに並べる方式をビッグエンディアン、下位バイトからさかさまにメモリに並べる方式をリトルエンディアンといいます。
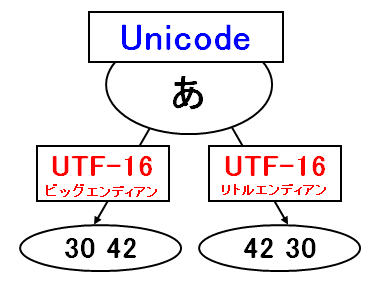
たとえば、Unicodeで定義されている「あ」という文字を、UTF-16のビッグエンディアンとリトルエンディアンで符号化すると下記のようになります(16進数表記)。
ビッグエンディアンでは「30」→「42」の順番であるのに対して、リトルエンディアンでは「42」→「30」のようにさかさまになっていることがわかります。
ビッグエンディアンは人間にとって直観的にわかりやすいという利点があり、一方リトルエンディアンはコンピュータにとって処理しやすいという利点があります。
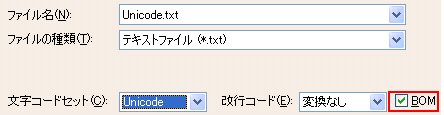
このようにUTF-16においては、ビッグエンディアンとリトルエンディアンの2種類があり、どちらのエンディアンで記述されたデータかを確実に判定するための特別なマークとなる符号として、BOM(Byte Order Mark)というものが用意されています。
BOMはテキストの先頭に付加され、ビッグエンディアンの場合は「FE FF」、リトルエンディアンの場合は「FF FE」(いずれも16進数表記)という値をとります。
Windowsメモ帳では必ずBOMが付加されますが、sakuraエディタなどではBOMを付加するか否かを選択することができます。
たとえば、Unicodeで定義されている「あ」という文字を、UTF-16のリトルエンディアンで保存した場合、BOMなしでは「42 30」、BOMありでは「FF FE 42 30」となります。
|






|