Unicode 〜UTF-8、UTF-16との違い〜では、Unicodeが世界中で使用される文字を集めた文字集合であるというお話をしました。
今回はこのUnicodeという文字集合を、もう少し詳しく見ていきましょう。
まずはたとえ話をします。
ある小学校を考えます。この小学校には1〜6まで6つの「学年」があり、1つの学年には1〜3までの3つの「クラス」があり、1つのクラスには1〜5までの5つの「班」があるとします。
1つの班に所属する生徒は6人で、班の中では1〜6まで6つの「班員番号」が割り当てられているすると、この小学校には6(班員番号)×5(班)×3(クラス)×6(学年)=540人の生徒がいることになります。
生徒は学年・クラス・班・班員番号を指定すれば一意に識別できます。学年・クラス・班・班員番号という4つの要素で540人を分類しているともいえます。
この例と同じように、Unicodeで定義されている世界中の文字は群・面・区・点という4つの要素で分類されます。
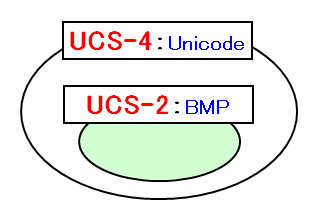
UCS-4という規格では128の群、256の面、256の区、256の点の組み合わせで文字を識別し、計算上、20億個以上の文字を収録することができます。
このUCS-4という文字集合の中で、「0番目の群」、「0番目の面」にある256(区)×256(点)=65536個の文字集合をUCS-2といいます。
UCS-2は、UCS-4の部分集合で、この中には世界で一般的に使用される文字、記号のほとんどが収録されています。
このことから、UCS-2をBMP(Basic Miltilingual Plane:基本多言語面)と呼ぶこともあります。
|






|