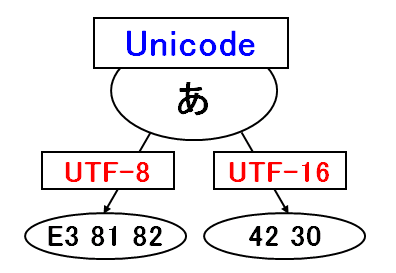
Unicode 〜UTF-8、UTF-16との違い〜では、Unicodeが世界中で使用される文字を集めた文字集合であり、実際の符号化にはUTF-8やUTF-16といった文字符号化方式(エンコーディング)を使用するというお話をしました。
当然、UTF-8やUTF-16といったエンコーディングが使用できる場合であれば、Unicodeで定義されている文字は問題なく使えるわけですが、それ以外のエンコーディングを使用しなければならない場合はどうでしょう?
例えば、Javaにおけるプロパティファイル(設定情報などを「キー=値」の形式で保存する拡張子が「properties」のファイル)の文字エンコーディングはISO 8859-1を使わなければいけないことになっています。
ISO 8859-1の符号表からもわかるように、ISO 8859-1で扱える文字の種類はごくわずかで、世界中の文字を定義するUnicode文字集合はおろか、日本語さえも扱えません。
このままではプロパティファイルの値に日本語を設定することができないわけです。
ISO 8859-1で定義されている文字だけを使って、Unicodeで定義されている文字(日本語など)を表現するにはどうしたらよいでしょうか?
そのような場合に使用されるのが、ユニコードエスケープ形式です。
ユニコードエスケープ形式では「\u」に、文字の符号位置を表す16進数の値を付加します。たとえば「あ」という文字であれば「\u3042」といった具合です。
(※ユニコードエスケープ形式の場合はUTF-16のビッグエンディアン。上の図ではリトルエンディアンなので「あ」が「4230」となっています。エンディアンについてはUnicode 〜エンディアンとBOM〜をご覧ください。)
この方法を使うと「\」と「u」、「0」〜「9」、「A」〜「F」の合計18種類の文字でUnicodeの全ての文字を表現できます。
(※正確には16ビット符号単位一つ(\uxxxx)で表現できるのはBMP文字のみで、その他の文字はサロゲートペアという仕組みを使って16ビット符号単位二つ(\uxxxx\uxxxx)で表現します。BMPについてはUnicode 〜UCS-4とUCS-2〜をご覧ください。)
ここで注意しなければならないのは、JavaのプロパティファイルにISO 8859-1で「\u3042」と書いて、それがUnicodeの「あ」に置き換わるのは、Javaという言語が内部で処理をしているからということです。
Javaの他にもJavaScript、Python、C++など、多くの言語でユニコードエスケープ形式をサポートしています。
|






|